🦜Q1 2026: Dashboard Developments and Presenting in Peru
With the start of April nearly upon us, I'm now back in Cambridge after a whirlwind trip to the Peruvian rainforest! This post outlines what I've been up to this year thus far, including updates about the Red List Dashboard, a description of my current agentic coding workflow, some initial thoughts for what's coming next, and finally reflections from several talks about my early PhD work (including presenting at the inaugural ICTC in Lima). If you make it to the end, you'll be rewarded with colourful pics of birds and frogs and butterflies from the Peruvian Amazon :)
Contents:
- Dashboard Developments
- My Agentic Coding Workflow
- Looking Forward: AI-Assisted Assessments
- Talks, Talks and More Talks
- Presenting in Peru and Birding in the Amazon
- Miscellaneous
- Final Reflections
Dashboard Developments: Towards A Living IUCN Red List of the World's Species
My main focus thus far this year has been continued development of the Red List Dashboard. When I first started on the dashboard back in December, my goal was simply to answer my own questions about what the biggest data gaps and maintenance challenges facing the IUCN Red List of Threatened Species were, given the Red List's importance as one of the world's most important conservation resources. However, the dashboard has rapidly evolved since then, and my hope is that bringing disparate biodiversity data sources together into a single user-friendly view will prove a highly useful resource for various Red List stakeholders.
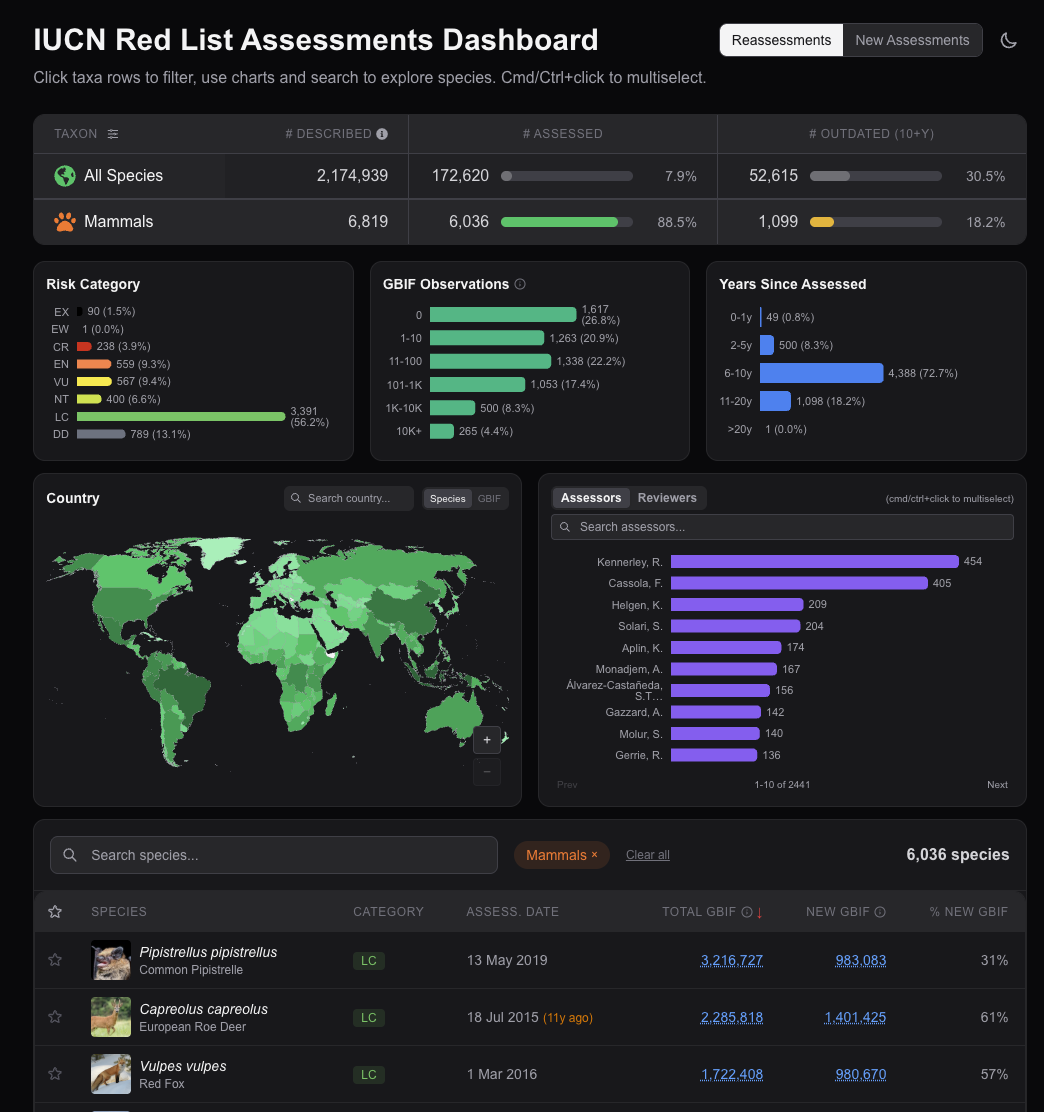
For now, the dashboard provides an easy way to navigate the 2+ million described species (yes, that's a lot of species!); using filters on country, taxonomy, conservation status, assessors, years since assessment; all the way down to individual species data from citizen science records (GBIF and iNaturalist), scientific literature (OpenAlex), use and trade data (CITES), and species experts' conservation status assessments (IUCN Red List). Together the idea is to bring all the key information about a species of interest from all the important biodiversity datasets all to one place.
Here's a video where I show the dashboard in action, for an example use case of helping prioritise reassessments of dragonflies and damselflies in India:
Part of our long-term vision here is that this could become part of a platform for open-source collaboration between assessors and agents (implementation-wise, Anil has suggested a great idea of linking to a Zulip server as a 'database' for hosting such communications). I've been thinking a lot recently about what differentiates humans from AI as AI agents become increasingly capable. And one of the key things is accountability – if we choose to use AI to help with some work, at the end of the day we still are the ones who need to take responsibility for the output and put a rubber stamp on it (and, crucially, be the one whose finger we point at if something goes wrong). As a result, whenever we are accountable for a piece of work, it's crucial that we still understand the data and reasoning AI uses well enough to verify it. To this end, having a visible, traceable, and transparent visual evidence-base view, as a shared reference for both assessors and agents, seems an extremely useful prospect.
Check out the dashboard for yourself at red.cst.cam.ac.uk, and let me know what you think!
My Agentic Coding Workflow: Managing parallel Claude Code agents
I've narrowed in on an AI coding workflow that I've found very productive for my work on the dashboard, and so I thought I'd talk through an example from it here. This workflow was heavily influenced by reading Boris Cherny, the creator of Claude Code, describe his own setup. I used this workflow to merge over 20 PRs last week, some of which comprised significant architectural improvements (e.g. redesigning the entire taxonomic system underlying the dashboard). I'd estimate this all would have taken me well over 3 months (at least 10x longer) before the age of AI coding agents. And consequently I probably wouldn't have even attempted it... It's a crazy time we live in. Anyways, here's a quick intro to my setup.
I work on a single repo for the dashboard, and often have a backlog of several features I want to add, which I try keep track of via GitHub Issues. When developing, I open up to 4 terminals at a time, and on each terminal instruct a separate Claude Code instance to work in a git worktree (which means agent can work on independent features without conflicting). What's my mental model for this? I think about how I would delegate this work to four different engineers in a team, each of whom would independently clone the repo (in fact, this is literally what happens with git worktrees, a new clone of the repo gets created on your filesystem – shoutout to my friend Ryan for showing me this).
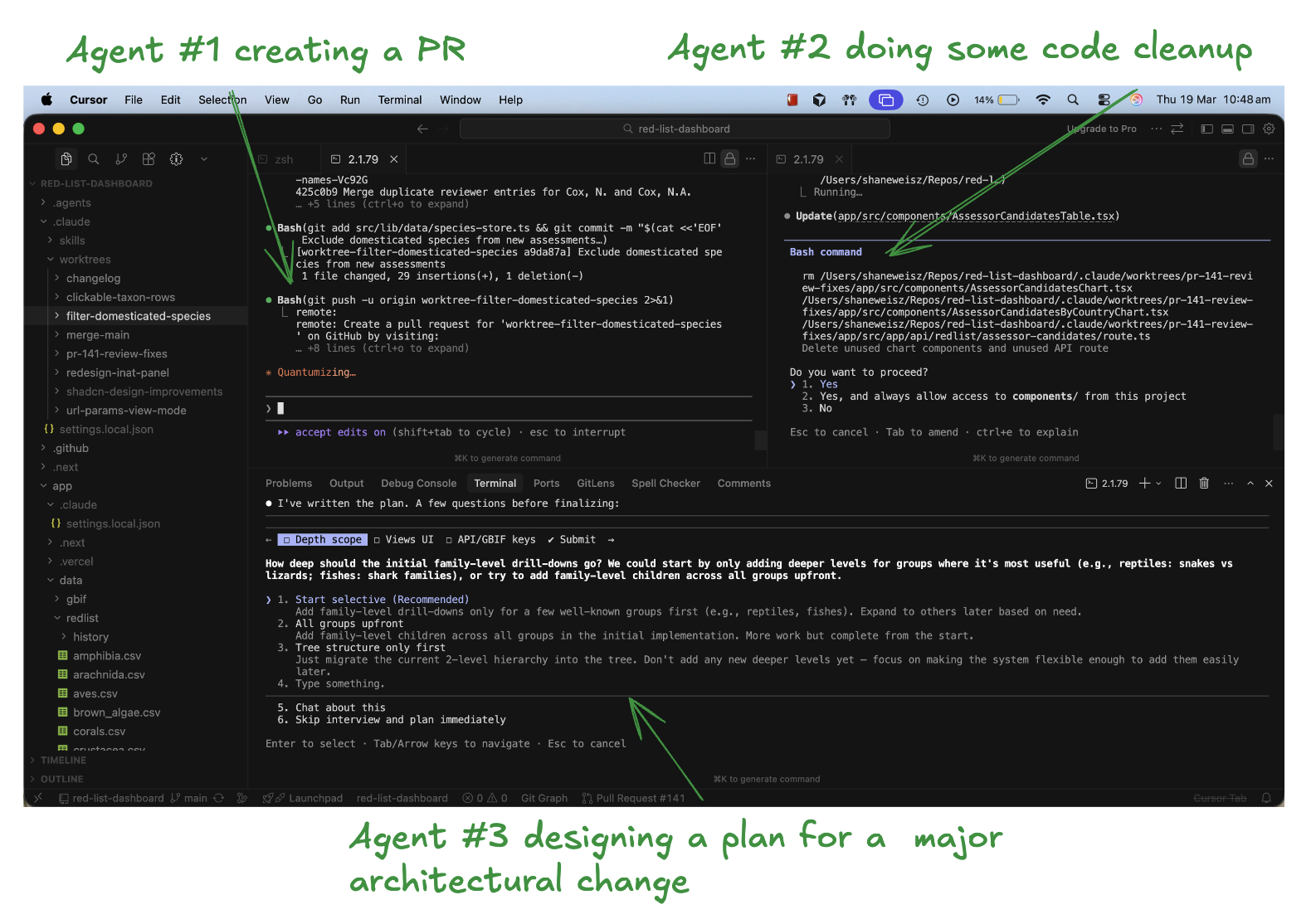
In each terminal, I then start to tackle one of my backlog issues. I start by working with Claude to come up with a plan. If it's well spec'd, I'll sometimes submit it to Claude Code web, so it can run in a sandboxed cloud container and doesn't need to check in with me for permissions. When I'm happy, I ask the agent to create a PR. For local changes that need back-and-forth collaboration, I'll often ask the agent to start a dev server, and occasionally use playwright so the agent can take screenshots of the app in action.
To avoid polluting the context window of the current chat (and likewise avoid having the main chat bias the context window for the investigation), I'll often ask the orchestrator agent to dispatch a subagent to investigate something (like how we'd assign an intern a task). For big structural changes, I'll ask the orchestrator agent to dispatch a couple agents for independent code reviews.
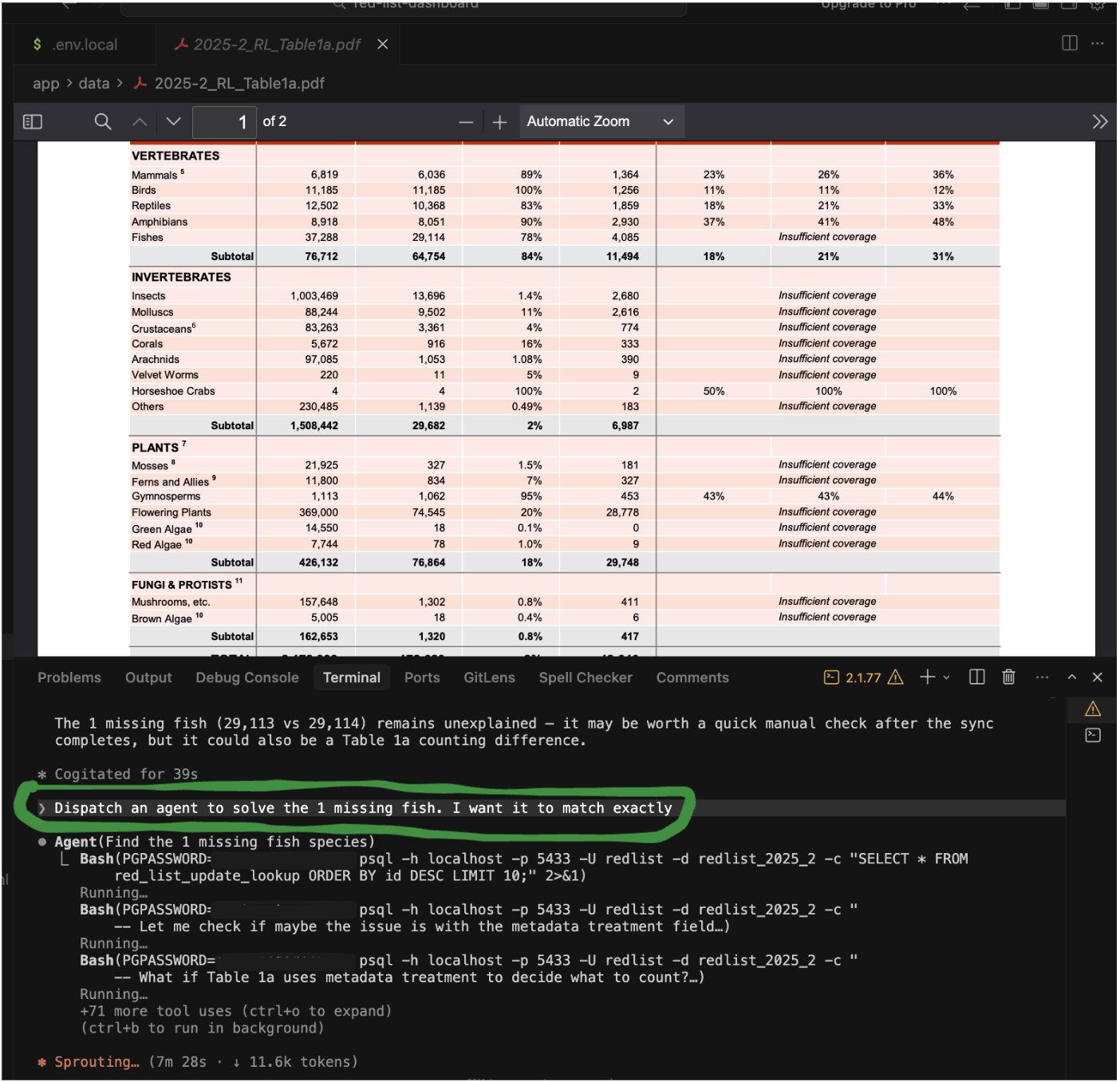
On the whole, the agents have succeeded with almost every task I've thrown at them. The one interesting stumbling block I ran into was with database design. I lost a bit of time on this, due to classic AI sycophantic tendencies at full play. It started by my deciding that it's time to upgrade to a Supabase database for the app's backend, to set us up for scale in the months to come. Naturally Claude Code fully agreed! But by the end of the week, after trying a lot of different approaches and schema designs, I concluded this was all premature optimisation – having a database would just slow down iteration, compared to the current approach of just serving static CSV and JSON files over the network. Getting some experience setting up a Supabase database was not a waste though – we will probably still want to set up a database at some point, and it was all valuable learning.
One other observation I had, was that database schema design felt like something I still had 'taste' for over the agents (for now at least). Part of the reason for this, I think, is that good schema design relies heavily on domain expertise, and deeply understanding the user's problems, for which I have context that the agent does not automatically have. And so of course it's now my job to clearly provide this context.
As a final note, I wanted to also mention my information diet for keeping up to date with AI developments. I subscribe to the writings of a few high-quality feeds: Simon Willison (co-creator of Django), Armin Ronacher, (creator of Flask) and Thorsten Ball (developer at Sourcegraph) – their writing is all highly recommended!
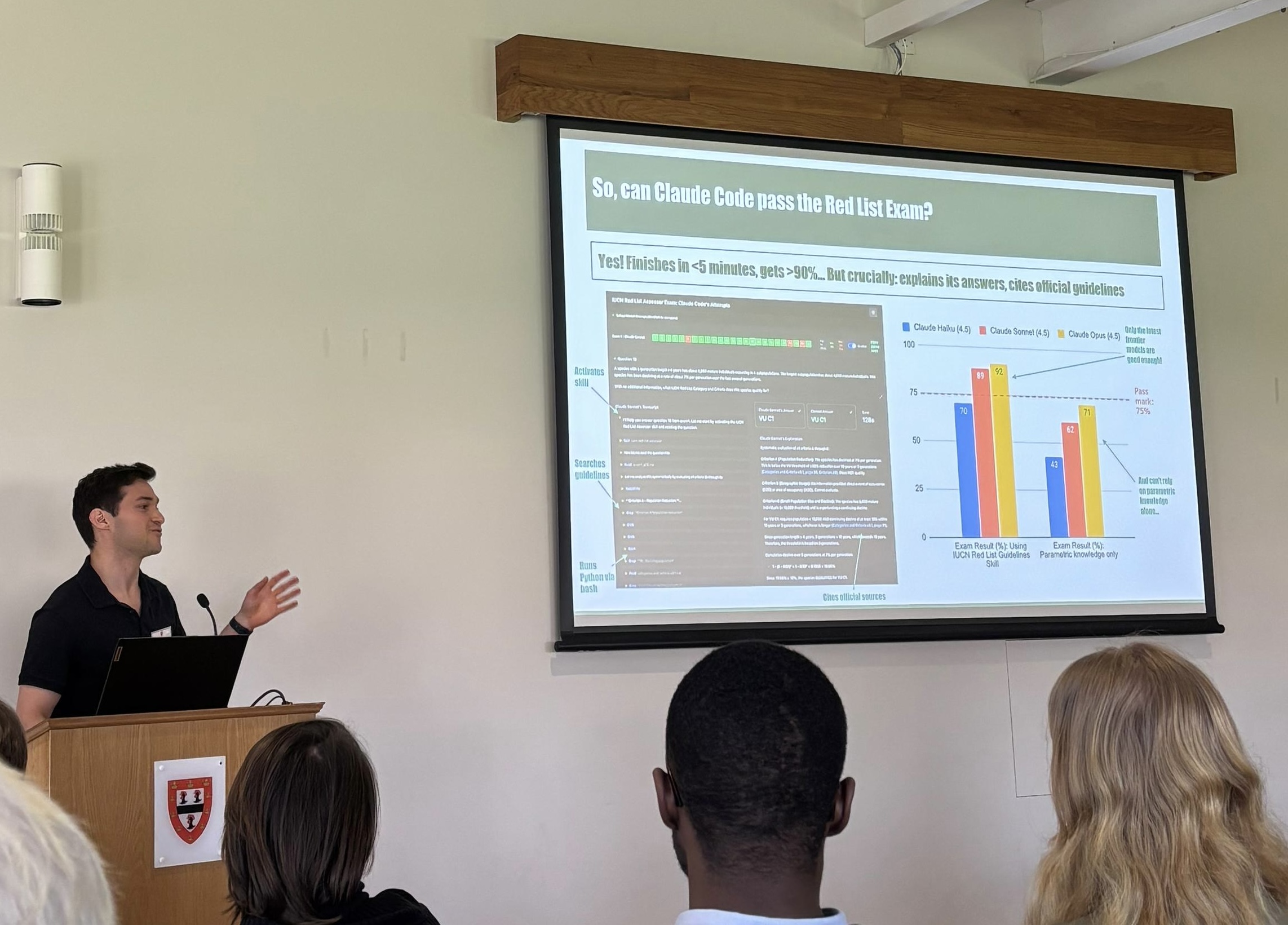
Looking Forward: AI-Assisted Red List Assessments
It's been widely felt like that there was another step-function change in AI coding agent abilities since November (Opus 4.5 and Codex 5.2), and again in February with Opus 4.6 and Codex 5.3. Consequently, I've become increasingly convinced we should all be raising our ambition about the tasks we attempt using AI coding agents. In the Red List case, this means using AI to draft completion of some SIS fields and even criteria parameter estimation (single-shot, with all tools allowed), and benchmarking how it does and where it fails. The agents will certainly make mistakes, as many of the most important information that goes into assessments is experts' knowledge that isn't encoded on the web. But benchmarking this will help narrow in and clearly understand where this boundary is. In the battle to scale out the Red List, we should be helping experts to focus exclusively on their unique insights into species' biology and ecology, and leaving all the mechanical work to AI. Red Listing is not a creative endeavor for humans; in fact it's the opposite, we want it to be as standardised, automated and consistent as possible.
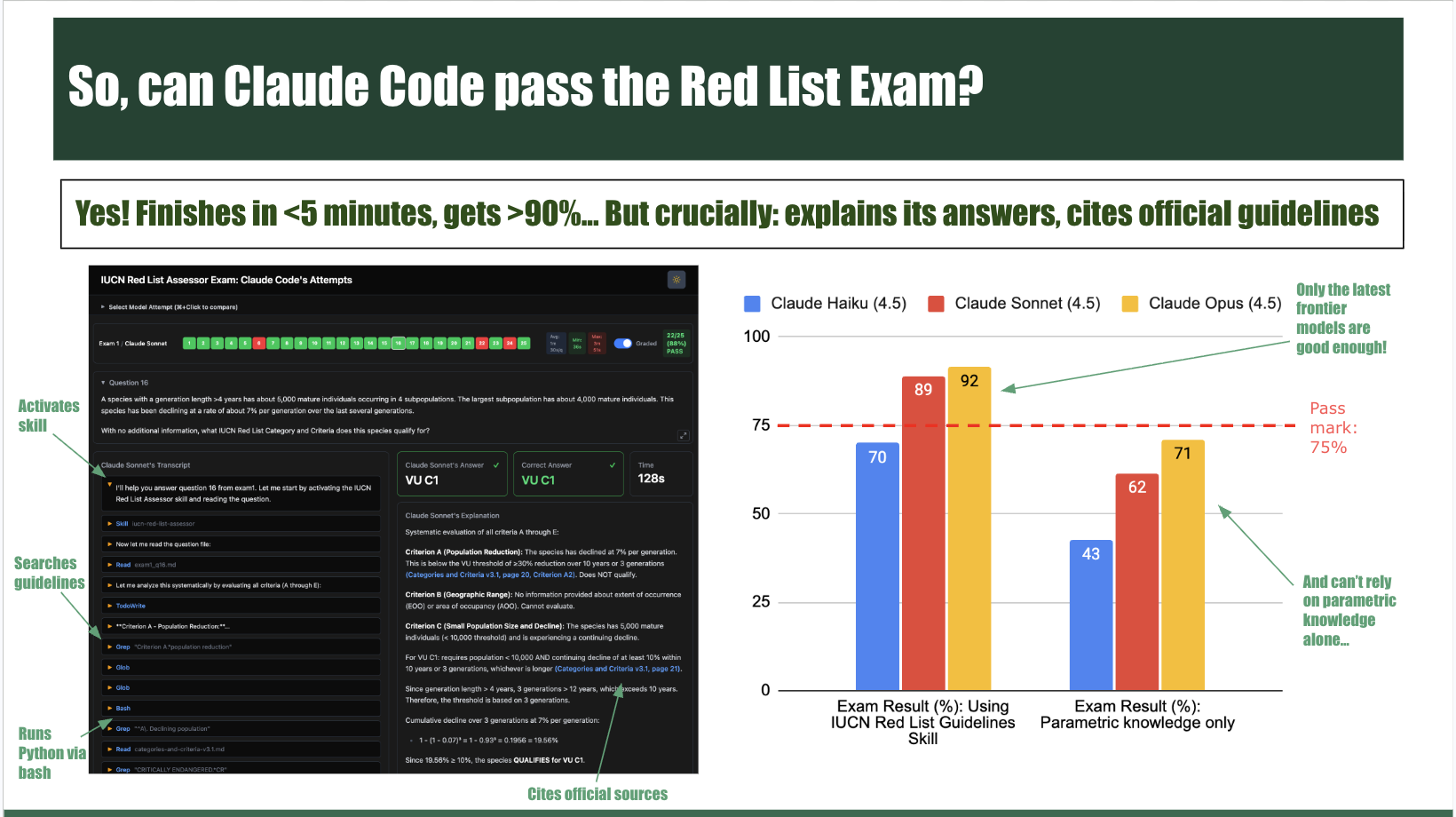
Moreover, from chatting with assessors during my time in Peru (more on that later), I'm increasingly realizing that even just starting assessments is a daunting undertaking. Many assessors are time-strained volunteers – and as a result anything that helps save time, and makes the process easier, would be highly valued. In the future, these AI-assisted draft assessments could use SIS Connect to feed into the exciting new SIS 3.0 platform (hopefully released end of this year) that stores the actual assessments.
In these benchmarking exercises, the batch of assessments received between each consecutive Red List release (e.g. between the November 2025 and June 2026 releases) provide a perfect window for running these experiments with the LLMs at 'full-power mode'. This is because we can give full access to the web, and know that the models can't 'cheat' (since assessments from this window will be restricted to the private SIS database, not accessible through the web, and won't be in the models' training data). For example, a possible methodology we could follow includes using Oct, Nov, Dec submissions for validation and tuning the system, then using the Jan, Feb, March submissions as a held-out test set. Evaluation could happen on multiple levels – firstly on the risk category for each criterion, but also on completion of SIS fields (habitat and ecology, use and trade etc), and perhaps even the range maps (using skills and multi-modal models). I'm excited to see where this goes and provide an update here in the months to come.
I also remain convinced that using AI for consistency checking of draft assessments, to reduce the workload on the Red List Unit, is a very feasible and useful win. A lot of the work here will be in the data-wrangling and eval creation using SIS data. With a lot of competing high-impact opportunities competing for my attention, it hasn't yet felt like the right time for me to work on it just yet. I hope to give more attention to this in the coming months, or else it could also possibly be a project I could co-supervise at some point (this could be a great setup – I could give guidance but leave the actual implementation to a Masters student for whom it's a well-sized project. I have experience in this from my time leading our ML team at Aerobotics, so I think I could be well-suited to such a role.) I've realised that as much as I'd love to participate with several important initiatives at the DAB (IUCN, KBA, CITES, habitat mapping, etc), I have only so much time, and need to be very careful where I invest my primary attention. And also remembering that some of the highest leverage work one can do is to empower others.
Finally, just a note on having had great chats with others who have developed useful tools for the Red List over the years, including Victor Cazalis who built sRedList, and Steve Bachman who has created several impactful tools including GeoCAT and Rapid Least Concern. Steve has been extremely friendly and helpful, and I'm hoping to spend a lot of time with him and his team in the coming months. His team at Kew submits many of the plant assessments worldwide, and with over 2000 newly described plant species each year on top of an existing backlog, any AI assistance would be very valuable. Steve has encouraged me to try submit an assessment or two myself, and possibly shadow an assessor at Kew for a couple days, both of which are fantastic ideas that I hope to take him up on.
Talks, talks and more talks: from the EEG to Peru
Over the past two months I've now given several talks about my initial PhD work, of varying lengths and to various audiences.
It started with a 3-minute thesis talk at a college dinner in early January, followed by a 45-minute presentation to computer scientists at the EEG in early February, a 7-minute talk to conservationists at ICTC in Lima in late February, a 1-minute elevator pitch to my PhD cohort last week, and a 10-minute talk to a general audience at the Jesus MCR conference. This has all been excellent experience for me, as it had been many years since I'd last done serious public speaking.
You can watch a YouTube recording of my talk at the EEG seminar here:
Presenting at ICTC in Peru and Birding in the Amazon
Finally, a note on my incredible trip to Peru at the end of February! I spent 3 nights at the inaugural International Conservation Technology Conference in Lima, followed by 6 nights in the Peruvian Amazon!

On the morning of the final day, I presented my work on using AI to support the Red List, as part of a great session on LLMs for Conservation, alongside Ali Swanson from Conservation International and Sarah Heubner from Smithsonian. The talk was well-received (lots of photos snapped from the audience) and afterwards we had good discussions sharing opportunities to use LLMs in conservation (including Hannah Murray hoping to use agentic LLMs to scan social media to detect illegal Pangolin trade...).

I also had a great chat with Mikel Maron from Earth Genome who approached me with questions after my talk. I'm a big fan of the work they do at Earth Genome. We discussed our shared recent experience of the huge impact one can have using agentic coding to build internal tools to transform operations at small orgs. His post about this is a great read.
Overall, I found ICTC very inspiring. I came away feeling like we have all the technological solutions ready for wide-scale biodiversity monitoring, for both land and sea, across taxa – and that it's just a matter of driving down costs now. For marine species, we have amazing technologies for monitoring at-sea with both on-board computer vision (e.g Tryolabs) and real-time satellite-monitoring via solutions like Ai2's Skylight. For land species, there's incredible innovations in drones and camera traps and bioacoustics and eDNA. Each of these have different taxonomic strengths: bioacoustics for birds, camera traps with lights to attract insects, GPS collars for mammals, drones for trees, eDNA for freshwater species, etc.
Some noteworthy projects I enjoyed learning about:
- Limelight Rainforest's $5M XPRIZE winning solution (crazy cool tech, insect monitoring camera traps, drone collecting eDNA, connected bioacoustic sensors etc.)
- ARM's 0.5W camera, £80.
- MothBox for low-cost insect monitoring
- Tryolabs for marine ship monitoring
- Ai2's SkyLight and EarthRanger. Both free. Ai2's model is incredibly powerful. Just need a couple philanthropists to fund top people. Interesting thought is how much good we could do for the world if we followed their model, and just convinced 1 or 2 billionaires to distribute StarLink and Solar Panels worldwide. A lot of the time, money does solve problems...
After ICTC, I then spent an incredible week at Los Amigos Biological Station, going on daily walks (and night walks!) through the Amazon. You can check out my eBird checklists here and my iNaturalist contributions here.
I was absolutely blown away by the diversity of birds, butterflies, insects, frogs, trees, sights and sounds... Here are some of my favourite colourful photos as promised:

Miscellaneous personal asides
- I'm a huge fan of Hannah Ritchie's work and Our World in Data more generally. After she recently released an awesome energy usage visualisation tool, I had a feature idea for shareable URLs, like I have in place for the dashboard. So I then thought, with the ease modern coding agents, why not try help by just adding the feature myself rather than pester her with a feature request... So I submitted a PR and sent her an email explaining what I'd done and how I'd tested it (along with a pointer to my dashboard if she were interested – given she wrote the great and highly-relevant Our World In Data article on extinction risk here). Although she ended up adding the feature herself rather than merging my PR, she took the time to write me a lovely warm response, which was very kind of her. My dashboard work has definitely been inspired by Our World In Data, so I was grateful to make this connection.
- One of my themes for the year was to slow down and simplify, after last term's busyness. Whilst this has reluctantly meant no more rowing or ballroom dancing, I've continued playing lots of sport (hockey, football, squash, tennis), ran the Cambridge half-marathon, spent lots of time visiting close friends in London, and have continued to frequent the Cambridge Buddhist Centre (along with a fantastic meditation retreat in Hertfordshire).
- I now have a busy few months ahead, with a fair amount of travel. I'm a groomsman for the wedding of one of my closest friends: we'll be celebrating Jono's Bachelors up in the Isle of Skye in mid-April, followed by some hiking adventures, and then l'll be going back to South Africa for a few weeks for the actual wedding in early-May (including a family trip to the Kruger of course!). In between, I'll be working on my first-year report, and getting going with the AI-Assisted Assessments experiments for the next phase of this project. I've also applied for a spot on the 2026 Machine Learning Summer School at Columbia University in New York for the end of June – another potentially exciting opportunity on the horizon.
Final Reflections
It's symbolic to now have my project idea up on Anil's website! He has patiently let me explore various directions in my early months, but it's nice to be converging on a focus area with my work on AI to support the Red List. I'm a big fan of Paul Graham's advice on the best ideas arising through evolution, rather than over-planning – I'm grateful Anil thinks similarly and has supported my ideas and work evolving over time:

Overall, it's been a fast-paced start to the year and time has flown. It also feels like a crazy time in the world more generally, filled with uncertainty for the future: AI exponentials, geopolitical tensions, and continuing alarming trends in climate and biodiversity. But in the face of uncertainty, the truths of mindfulness are more important than ever: all we can do is pay close attention to the present moment, and respond to its demands as best we can. Happy Easter everyone!